

- Three-model series spans manipulation, navigation and world modeling
- Shift signals move from digital reasoning to physical task execution
Alibaba Group has released a new embodied AI model family under its Qwen series, introducing three core systems designed to give robots capabilities in manipulation, navigation and physical-world reasoning.
The company on Tuesday unveiled Qwen-RobotManip, Qwen-RobotNav and Qwen-RobotWorld — respectively a vision-language-action manipulation model, a navigation model and a world model — marking the first full embodied intelligence stack in its Qwen foundation model lineup.
The models can be deployed independently or jointly, forming a unified base for robotic systems operating in real-world environments.
-1024x336.jpg)
From language models to physical intelligence
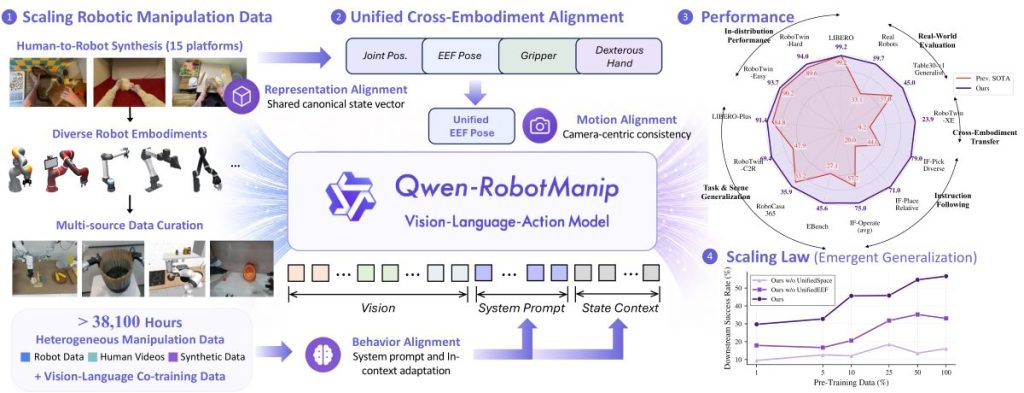
Qwen-RobotManip is designed for physical interaction tasks such as grasping and tool use.
Unlike conventional VLA models that often degrade when transferred across hardware, it introduces a unified 80-dimensional action representation intended to standardize motion control across different robot platforms.
The model can adapt with limited feedback, according to the company.
It was trained on more than 38,000 hours of pretraining data using only open-source datasets, avoiding reliance on proprietary data collection — a departure from common industry practices.
In third-party testing on the RoboChallenge Table30 v1 benchmark across 30 real-world tasks and four robot platforms, two versions of the model ranked first and second.
Tasks included turning water taps, plugging in Ethernet cables and dual-arm frying tasks such as pouring fries, with evaluators noting it showed stability in basic operations and strong performance on complex tasks.
On the Libero-Plus benchmark, the model achieved a 91.4% success rate.
Notably, Qwen released a VLA model in early June, aiming to combine vision, language and motion generation into a single system for robots.
-1024x509.jpg)
Manipulation, navigation and world modeling unified
Qwen-RobotNav focuses on mobility and instruction-following in physical space. It unifies multiple navigation scenarios — including language-based instructions, target search and autonomous driving — into a single framework.
To address issues of memory overload or loss in prior systems, it introduces a task-adaptive observation mechanism that dynamically adjusts what the model retains.
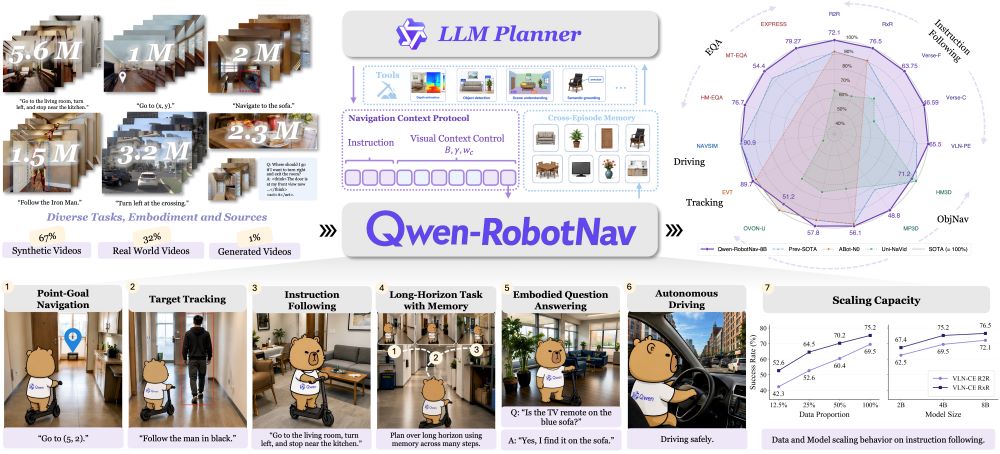
In testing, a Unitree Go2 quadruped robot running the system was able to interpret a request to “find a suitcase whose location is unknown,” autonomously patrol its environment and complete the search using visual reasoning.
Benchmark gains signal push into real-world robotics
Qwen-RobotWorld is positioned as a world model for physical prediction and planning, simulating likely future states of robotic actions based on physical constraints.
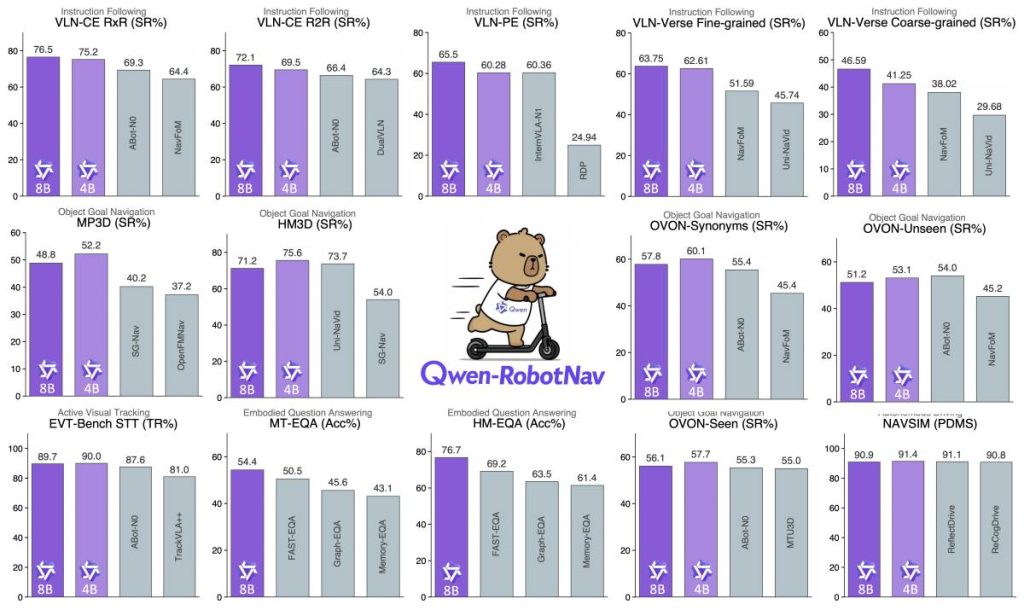
The company said it outperformed peers across four major benchmarks, particularly in physical consistency and motion fidelity.
The release extends Alibaba’s Qwen3.7-Max foundation model into embodied intelligence, reflecting a broader shift from digital reasoning systems toward interaction with the physical world.
The company also disclosed an internal framework, Qwen-RobotClaw, which uses the three models as tool components to enable open-ended task execution, long-horizon failure recovery and embodied question answering — indicating early integration of the system into more general robotic agents.

